Dana86
-
Posts
52 -
Joined
-
Last visited
Everything posted by Dana86
-

Calculation Mistakes in Large Arrays
Dana86 replied to Dana86's topic in AutoIt General Help and Support
In an experimental data scientist type environment, there is a lot of copy and pasting to get things done faster. 99.9% of experiments fail, so rapid development is very important. Scalability and stability comes later after successful initial experiments. Some days I work for 16 hours on longer experiments. An experiment is like an idea, but a very long drawn out idea that takes many hours to develop and test. Most ideas are are versions of older failed experiments and they get reused. -
Calculation Mistakes in Large Arrays
Dana86 replied to Dana86's topic in AutoIt General Help and Support
ByC() was meant to be like the python equivalent of df.loc[] with labels instead of col numbers. Makes experiments more robust, scalable and possible for future data manipulation. iProfit=round((Price-df.loc[r,'EntryPrice'])*df.loc[r,'Size'],2) -
Calculation Mistakes in Large Arrays
Dana86 replied to Dana86's topic in AutoIt General Help and Support
Thanks for being honest, I've tried R and Python the process of going from theory to simulation to implementation is much slower. Tho, I changed a few Au3 funcs to reflect python a bit to make my life easier coding between the two languages. -
Calculation Mistakes in Large Arrays
Dana86 replied to Dana86's topic in AutoIt General Help and Support
Ya, C and C++ is super fast but its way slower & harder to write. I can write a few thousand lines of code on Au3 in a day vs only a few hundred lines with C or C++. -
Calculation Mistakes in Large Arrays
Dana86 replied to Dana86's topic in AutoIt General Help and Support
I make my living with Algo-Trading and due to the nature of my work I can not share my code with everyone. -
Calculation Mistakes in Large Arrays
Dana86 replied to Dana86's topic in AutoIt General Help and Support
Not, the type of demeanor that results in a better community of developers??? -
Calculation Mistakes in Large Arrays
Dana86 replied to Dana86's topic in AutoIt General Help and Support
The data file is too large to upload into this forum. If there any functions that you need I'll provide them. But really I am just getting different calculation results between the use of with and without the use of the function Number(). The miscalculations are reproduceable across a large set of simulations I do, this is just one example. I get completely different results when I replace ByC() with ByCn(). This is a less complex simulation I do for forex, there are more complex simulations for equities that uses parallel processing. -
I wish I had more time to game! But been too obsessed with writing new simulations & testing theories with autoit and python.
-
I use $CmdLine for keeping my python APIs from crashing. There are a lot of weird unexpected crashes in other people's wrappers. #include-once #include "E:\Autoit_FibFinder\Include\MyFunctions.au3" Globals() Func Globals() Global $lr=$CmdLine[0] Global $ProgramDir=$CmdLine[1] Global $PingDir=$CmdLine[2] EndFunc Main() Func Main() While 1 Sleep(5000) AlwaysOn(10) WEnd EndFunc Func AlwaysOn($MaxWait) XWriteTxt($PingDir,0) For $i=1 To $MaxWait If Number(XReadTxt($PingDir))=1 Then ;~ MsgBox($MB_SYSTEMMODAL,"$PingDir",$PingDir) ;~ MsgBox($MB_SYSTEMMODAL,"Ping",Number(XReadTxt($PingDir))) Return 1 EndIf Sleep(1000) Next If Number(XReadTxt($PingDir))=0 Then ;~ MsgBox($MB_SYSTEMMODAL,"$PingDir",$PingDir) ;~ MsgBox($MB_SYSTEMMODAL,"Ping",Number(XReadTxt($PingDir))) XWriteTxt($PingDir,1) Sleep(500) Run($ProgramDir) Sleep(5000) Return 0 EndIf EndFunc As stated above it wouldn't work for my case use AlgoTrading because the data files are too large. And new args need to be inserted whilst the large data csv is loaded into a global array once.
-
Func C(ByRef $a,$Label);Returns Index Num Col of Seek Label in Array Local $lr=UBound($a,1)-1 Local $lc=UBound($a,2)-1 Local $iLabel="None" For $c=0 To $lc $iLabel=$a[0][$c] If $iLabel=$Label Then Return $c Next Debug("[ERROR]Label Not Found! "&$Label) Return "[ERROR]" EndFunc Func ByCn(ByRef $a,$Row,$Label) Return Number($a[$Row][C($a,$Label)],3) EndFunc Func ByC(ByRef $a,$Row,$Label) Return $a[$Row][C($a,$Label)] EndFunc When I run complex calculations in large arrays derived from .csv files with ByC() (returned without Number()) I get calculation errors. The calculation errors (straight up bogus outputs) seem to be gone after running the returns with Number(). Normally these errors aren't there when running smaller and less complex calculations. I was running 16 parallel processors and calculations still take 30 minutes, when I add the Number() function calculations take up to 24 hours... Is there a faster alternative to Number() or a way to import the arrays as float values & bypass these calculation errors? Thanks!
-
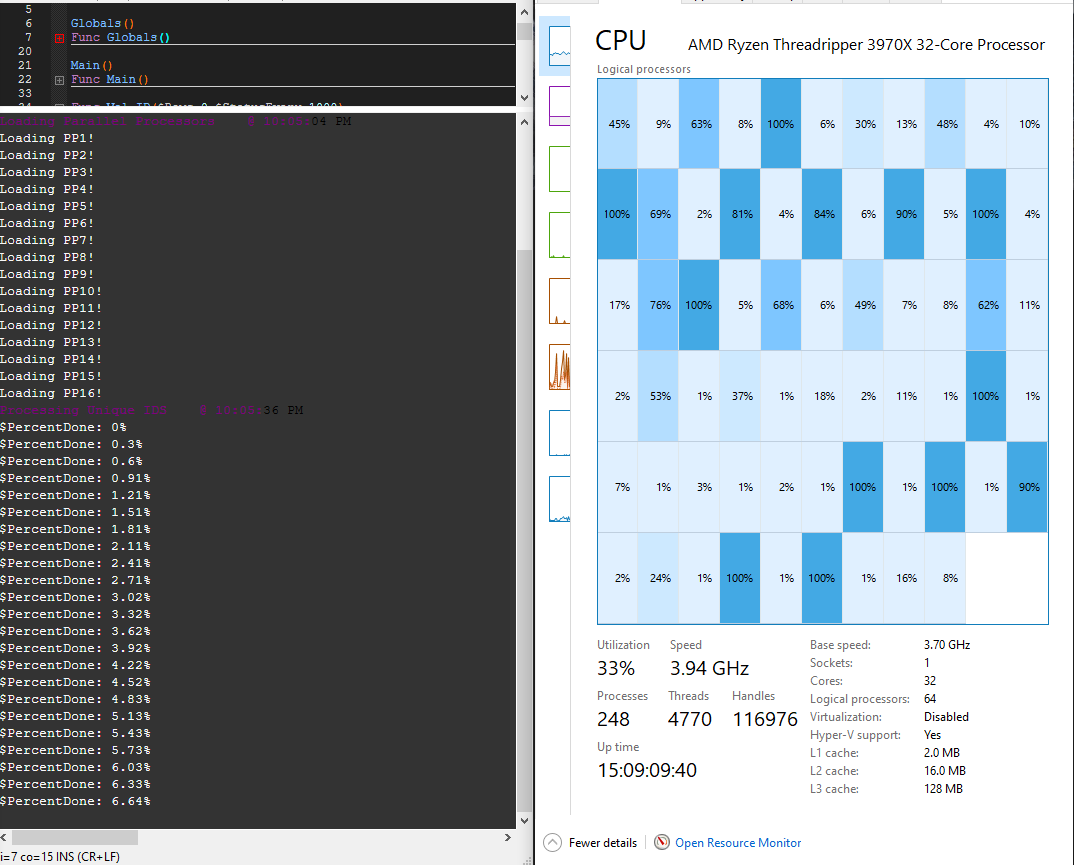
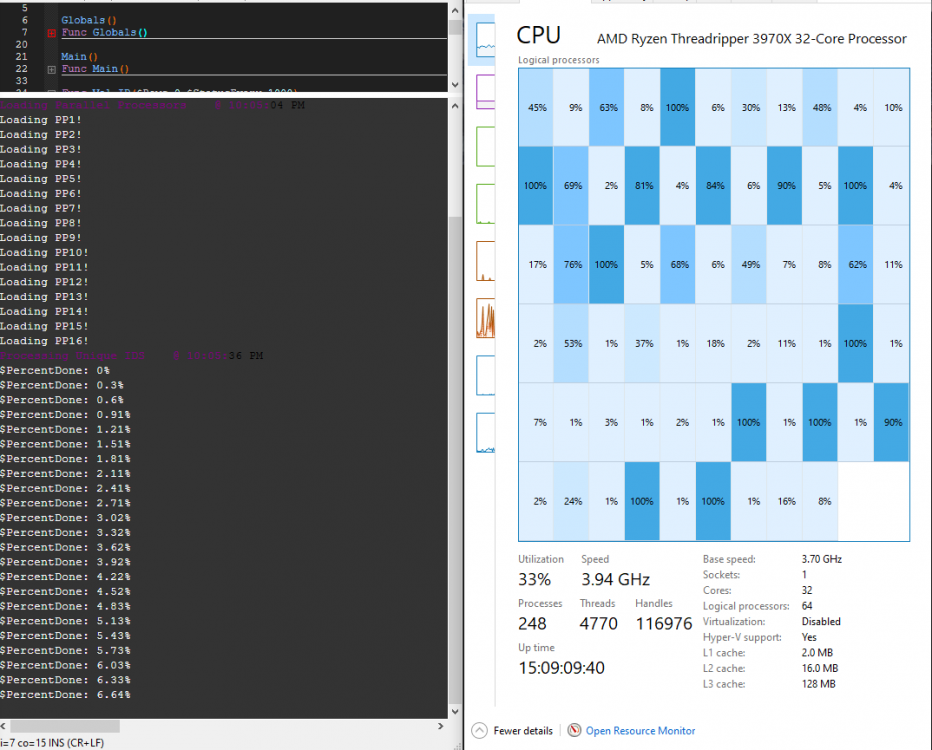
[Update]Ported everything over to my workstation & it's using 35% of my 64 threads with 16 PP(parallel processors)! I am processing data that usually takes 3-4 hours on my laptop in 10 minutes!
-
I could go that route but things get complicated as the csv file is then used with another python app. CSV hasn't failed me yet.
-
Thank you, that was actually my main question. I wanted to use this method to create AI vs logic through .csv and .json files which are limiting. Parallel processing is a must for AI with Au3 vs Python has built in multi threading capabilities for AI & ML.
-
For my particular use case, command-line arguments wouldn't work because all 4 processors run off of the same csv file with 500k-1mill rows. The CSV load time is around 10-30 seconds each load. It is much faster to issue new arguments and executions through .txt files. The processors maintain global csv arrays in a while loop while waiting for new commands. ;~ Globals() Func Globals() Global $a CSVToArray($a,"E:\Data.csv") Global $lr=UBound($a,1)-1 Global $done[1] Global $UniqueCt=0 ;<-----------------------SETTINGS Global $sd=0.10 Global $mrt=1 Global $mp=1 Global $mpt=1 EndFunc ;Main(ReadTxt("PID")) Main(1) Func Main($Num) Globals() While 1 If ReadTxt("P"&$Num&"_NewJob")=1 Then WriteTxt("P"&$Num&"_NewJob",0) WriteTxt("P"&$Num,1) WriteTxt("Accepted",1) Local $Row=ReadTxt("ProcessRow") ;Debug("Processing Row: "&$Row) If $Row>10 Then $Row=$Row-10 Tracker(ReadTxt("ProcessID"),$Row) WriteTxt("P"&$Num,0) EndIf Sleep(250) WEnd EndFunc
-
It objectively saves time in my particular use case. It has to process 500k-1mill rows of .csv data in multiple layers of nested for loops. Tho it would be nice if I could make build a library for easier & faster execution in the future.
-
Ya, I run the same .exe with different arguments on my other computer just fine. But for some reason it doesn't work for this particular laptop, not entirely sure why.
-
Right now I am manually building parallel processors for multithreading. Tested, definitely 3x faster processing time. But I was wondering if there is an au3 function to auto output sections of code into sperate temporary .au3 files & then automatically compile them into .exes, use them for processing data then delete the temp .au3 file & .exes after processing that information? Func FindProcessor($r,$ID) ;Debug("FindProcessor") WriteTxt("ProcessID",$ID) WriteTxt("ProcessRow",$r) WriteTxt("Accepted",0) Sleep(250) For $i=1 To $MaxJobs If ReadTxt("P"&$i)=0 Then WriteTxt("P"&$i&"_NewJob",1) ;Debug("PID: "&$i&", ProcessID: "&$ID&", ProcessRow: "&$r) Do Sleep(250) Until ReadTxt("Accepted")=1 Return 1 EndIf Next Return 0 EndFunc Func LoadProcessors() Debug("Loading Parallel Processors") For $i=1 To $MaxJobs WriteTxt("P"&$i,0) WriteTxt("P"&$i&"_NewJob",0) ShellExecute(@ScriptDir&"\Processor_"&$i&".exe") Sleep(2000) Next EndFunc
-
SSD Size & Longevity/Resilience/Speed
Dana86 replied to Dana86's topic in AutoIt Technical Discussion
Thanks guys that answered all of my questions! -
My program is reading, writing & processing gbs of data everyday. 1. Will this eventually damage & reduce SSD write/read speed over time? 2. Would running programs off of multiple dedicated smaller SSDs help increase/retain performance? If anyone knows that would be much appreciated! I've been planning on investing in some SSDs!
-
I use both Autoit & Python, I just wrote a private library to make Au3 emulate to Python & a Python library to emulate Au3 Not the most github friendly solution but it gets things done much faster. You can build a simple parallel computing solution with Autoit pretty easily, with some .txt files or databases as variable inputs & outputs and just use the complied .exe code as an object. Somethings like Python's Tensorflow is harder to replace with Autoit, but because Au3 is so much easier & faster to code, you can build a simple decision tree machine learning library with Autoit in as little as a few days. I will admit tho JSON is wayyy harder to read & write in Au3 vs Python.
-
Thanks guys!
-
Does anyone know if computing power is reduced when rounding floats into smaller decimal places? I'm working with large datasets & nested for loops. Thanks!
-
Machine Learning Algorithms & AI
Dana86 replied to DynamicRookie's topic in AutoIt General Help and Support
This guy has some great insight into the problem... -
Machine Learning Algorithms & AI
Dana86 replied to DynamicRookie's topic in AutoIt General Help and Support
Any help is much appreciated!😀💖 -
Machine Learning Algorithms & AI
Dana86 replied to DynamicRookie's topic in AutoIt General Help and Support
I've long identified the piece of code that uses the most CPU power but... I don't know how to optimize it... this is the best I could come up with, it made it mildly faster sometimes... I have a 6 core 4.9ghz cpu... perhaps I can write a new _ArrayFuzzyMax function & it might speed things up but ill lose some accuracy. Local $Max30=_ArrayMax($Range,1,$LRow-30,$LRow,$High) Local $Max60=_ArrayMax($Range,1,$LRow-60,$LRow,$High) Local $Max120_0 Local $Max120_1 Local $Max120_2 $Max120_2=_ArrayMax($Range,1,$LRow-120-2,$LRow-2,$High) If $Range[$LRow-1][$High]>$Max120_2 Then $Max120_1=$Range[$LRow-1][$High] Else $Max120_1=_ArrayMax($Range,1,$LRow-120-1,$LRow-1,$High) EndIf If $Range[$LRow][$High]>$Max120_1 Then $Max120_0=$Range[$LRow][$High] Else $Max120_0=_ArrayMax($Range,1,$LRow-120,$LRow,$High) EndIf Local $Min30=_ArrayMin($Range,1,$LRow-30,$LRow,$Low) Local $Min60=_ArrayMin($Range,1,$LRow-60,$LRow,$Low) Local $Min120_0 Local $Min120_1 Local $Min120_2 $Min120_2=_ArrayMin($Range,1,$LRow-120-2,$LRow-2,$Low) If $Range[$LRow-1][$Low]<$Min120_2 Then $Min120_1=$Range[$LRow-1][$Low] Else $Min120_1=_ArrayMin($Range,1,$LRow-120-1,$LRow-1,$Low) EndIf If $Range[$LRow][$Low]<$Min120_1 Then $Min120_0=$Range[$LRow][$Low] Else $Min120_0=_ArrayMin($Range,1,$LRow-120,$LRow,$Low) EndIf