Search the Community
Showing results for tags 'unicode'.
Found 16 results
-
 I use blat.dll from the free mailer https://www.blat.net - but it turns Unicode characters in my body, etc. to Gibberish. Here's what I currently do: DllCall("blat.dll,"int","Send","str", "list of Blat parameters...") Can you please tell me how to also employ the file blatdll.h?
I use blat.dll from the free mailer https://www.blat.net - but it turns Unicode characters in my body, etc. to Gibberish. Here's what I currently do: DllCall("blat.dll,"int","Send","str", "list of Blat parameters...") Can you please tell me how to also employ the file blatdll.h? -
 Hi all, I'm reading the file https://msedgedriver.azureedge.net/LATEST_RELEASE_83 using WinHTTP, and the string I get back looks like this when I view this file in Scite -- xEFxBFxBF83.0.478.54 Here's what I've come up with as a means to strip off the Unicode BOM from the beginning of the string -- If Asc($sDriverLatest) = 255 Then ConsoleWrite("Unicode detected!" & @CRLF) $sDriverLatest = BinaryToString($sDriverLatest, $SB_UTF16LE) If Asc($sDriverLatest) = 63 Then $sDriverLatest = StringMid($sDriverLatest,2) ; skip ? EndIf ConsoleWrite("Latest=" & $sDriverLatest & @CRLF) Is there a more reliable way to eliminate these unicode characters? Dan
Hi all, I'm reading the file https://msedgedriver.azureedge.net/LATEST_RELEASE_83 using WinHTTP, and the string I get back looks like this when I view this file in Scite -- xEFxBFxBF83.0.478.54 Here's what I've come up with as a means to strip off the Unicode BOM from the beginning of the string -- If Asc($sDriverLatest) = 255 Then ConsoleWrite("Unicode detected!" & @CRLF) $sDriverLatest = BinaryToString($sDriverLatest, $SB_UTF16LE) If Asc($sDriverLatest) = 63 Then $sDriverLatest = StringMid($sDriverLatest,2) ; skip ? EndIf ConsoleWrite("Latest=" & $sDriverLatest & @CRLF) Is there a more reliable way to eliminate these unicode characters? Dan -
 Good morning, I am trying to read a Unicode utf8 string from a perl subprocess via StdoutRead. I use an AUtoIt GUI and display result in an 'Edit' control (see my code below) using 'Courier New', a font that can handle Unicode characters. I was expecting a result looking like (CMD console): ++$ chcp 65001>NUL: & perl -Mutf8 -CS -e "use 5.018; binmode STDOUT,q(:utf8); say qq(\x{03A9})" & chcp 850>NUL: Ω Instead I get someting like this (see downward the screen copy): ++$ chcp 1250>NUL: & perl -Mutf8 -CS -e "use 5.018; binmode STDOUT,q(:utf8); say qq(\x{03A9})" & chcp 850>NUL: Ω Obviously while I was expecting to receive an utf8 char, it seems to have been converted to Windows ANSI codepage 1250 (Windows default for Western/Central Europe, right ?) What am I doing wrong? Is there someone who could guide me? Here is my code and my output in the GUI. Creating and configuring the Edit control: Local $Edit1 = GUICtrlCreateEdit( "", 20, 110, 780, 500, BitOr($GUI_SS_DEFAULT_EDIT,$ES_MULTILINE,$ES_READONLY) ) GUICtrlSetData($Edit1, "This field will contain text result from external Perl command") GUICtrlSetFont($Edit1, 10, $FW_THIN, $GUI_FONTNORMAL, "Courier New") Executing Perl command (note: `-Mutf8` and `-CS` garantees that I work in utf8 and STDOUT accepts wide-characters): local $ExePath = 'perl.exe -Mutf8 -CS ' ;~ if perl in PATH, no need for full path C:\Perl\bin\perl.exe local $Params = '-e "use 5.018; use utf8; use charnames q(:full); binmode STDOUT,q(:utf8);' & _ 'say scalar localtime; say qq(\N{GREEK CAPITAL LETTER OMEGA})"' local $Cmd = $ExePath & ' ' & $Params Local $iPID = Run($Cmd, "", @SW_HIDE, BitOR($STDERR_CHILD, $STDOUT_CHILD)) Reading STDOUT and displaying it into the Edit control: While 1 $sOutput &= StdoutRead($iPID) If @error Then ; Exit the loop if the process closes or StdoutRead returns an error. ExitLoop EndIf WEnd If $sOutput <> '' Then GUICtrlSetData($Edit1, $sOutput) EndIf And now, what I get on my GUI:
Good morning, I am trying to read a Unicode utf8 string from a perl subprocess via StdoutRead. I use an AUtoIt GUI and display result in an 'Edit' control (see my code below) using 'Courier New', a font that can handle Unicode characters. I was expecting a result looking like (CMD console): ++$ chcp 65001>NUL: & perl -Mutf8 -CS -e "use 5.018; binmode STDOUT,q(:utf8); say qq(\x{03A9})" & chcp 850>NUL: Ω Instead I get someting like this (see downward the screen copy): ++$ chcp 1250>NUL: & perl -Mutf8 -CS -e "use 5.018; binmode STDOUT,q(:utf8); say qq(\x{03A9})" & chcp 850>NUL: Ω Obviously while I was expecting to receive an utf8 char, it seems to have been converted to Windows ANSI codepage 1250 (Windows default for Western/Central Europe, right ?) What am I doing wrong? Is there someone who could guide me? Here is my code and my output in the GUI. Creating and configuring the Edit control: Local $Edit1 = GUICtrlCreateEdit( "", 20, 110, 780, 500, BitOr($GUI_SS_DEFAULT_EDIT,$ES_MULTILINE,$ES_READONLY) ) GUICtrlSetData($Edit1, "This field will contain text result from external Perl command") GUICtrlSetFont($Edit1, 10, $FW_THIN, $GUI_FONTNORMAL, "Courier New") Executing Perl command (note: `-Mutf8` and `-CS` garantees that I work in utf8 and STDOUT accepts wide-characters): local $ExePath = 'perl.exe -Mutf8 -CS ' ;~ if perl in PATH, no need for full path C:\Perl\bin\perl.exe local $Params = '-e "use 5.018; use utf8; use charnames q(:full); binmode STDOUT,q(:utf8);' & _ 'say scalar localtime; say qq(\N{GREEK CAPITAL LETTER OMEGA})"' local $Cmd = $ExePath & ' ' & $Params Local $iPID = Run($Cmd, "", @SW_HIDE, BitOR($STDERR_CHILD, $STDOUT_CHILD)) Reading STDOUT and displaying it into the Edit control: While 1 $sOutput &= StdoutRead($iPID) If @error Then ; Exit the loop if the process closes or StdoutRead returns an error. ExitLoop EndIf WEnd If $sOutput <> '' Then GUICtrlSetData($Edit1, $sOutput) EndIf And now, what I get on my GUI: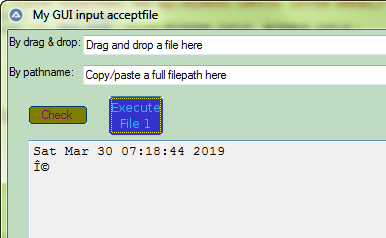
-
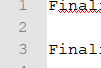
'Final' ; <========= problem between F and i 'Final' ; <========= problem between F and i 'Final' ; <========= Notepad ANSI, no problem Final PostgreSQL complains about that red dot. Notepad++ marks the first word. Notepad said it contains Unicode. Saved as ANSI and put back. Red dot is gone. the Text is inserted manually into an AutoIt Input box. Things get done to it, and it ends up in a SQL database. The data seems fine, but when I start generating reports, all kinds of funny problems show up. If I can ID that character, I can remove it. Any ideas?

-
Hi dear With this script you can print Unicode text in the CMD screen the script is easy to use just you write the text that contains Unicode in the first input and the script automatically reflect the code in the second input you can copy the text to the clipboard or you can try printing the text in the CMD window I apologize to everyone for colors and shape if not appropriate I'm a blind man and I do not see Thank you for your understanding Greetings to all of youCmdUtM.au3
-
I need help with unicode char ü I get some text from online json but if try to read 4 example Zürich I heave Zürich. How can I convert with autoit unicode to a clear character readable? thx
-
Hello I'm using the code below to send mails using our internal relay server. We got a Helpdesk system named Remedy. Our users can send us a mails using outlook 2010, and we'll get a ticket. The problem is if I send a mail using the above script our ticket system can't display unicode characters, like ex: Æ Ø Å. It will display them as: questionmarks: "? ? ?" inside our ticket system. In the outlook inbox it looks fine showing unicode symbols, but in our ticket system the unicode characters will be replaced by questionmarks. The thing is, if they send a mail using outlook, it works fine, but using the script above it doesen't. I tried to save my script with encoding: UTF-8 with BOM, but it didn't fix it. All suggestions are very welcome
-
This is a Wrapper for Pugixml, made with C++ by me and uses the version 1.2. Description pugixml is a light-weight C++ XML processing library. It consists of a DOM-like interface with rich traversal/modification capabilities, an extremely fast XML parser which constructs the DOM tree from an XML file/buffer. pugixml enables very fast, convenient and memory-efficient XML document processing. However, since pugixml has a DOM parser, it can't process XML documents that do not fit in memory; also the parser is a non-validating one, so if you need DTD or XML Schema validation, the library is not for you. License The Xml parser(Pugixml) is distributed under the MIT license: This means that you can freely use pugixml in your applications, both open-source and proprietary. Features Load/save XML files to an in-memory document object model (DOM).Add name/value attribtes to nodes.Numerous methods for iterating over the nodes in a document.Built in XPath.Full Unicode support.MsXml Independent.Has about 47 Functions.Works on: Microsoft Windows 2000, XP, Server 2003, Vista, 7, Server 2008. 32 bit ____________________________________________________________________________________________ Not supported any more due the fact that I had a hard drive failure therefore lost the source code of the DLL. ____________________________________________________________________________________________ Download Link AXml.zip Note: I have also included a 64bit DLL but as I don't have a 64bit computer it remains untested.
-
 Non-important short long story: I was facing several troubles when working with a webservice made in PHP and an AutoIt client. The AutoIt client had to send some data to the PHP webservice, then it would get back part of the data (with additional data) back to AutoIt, then send through Json to another webservice and end up in a TV system (huff). As I was using mostly Inet* functions, working with charsets became complicated, as it had to encode, decode, encode... and the mess is done. On the other end I was receiving a completely buggy string with several problems in accentuated characters (note that I live in Brazil, we speak portuguese that contains a lot of accented chars - Ááãç...). I tried and tried mixing utf_encodes and decodes everywhere, in PHP and Javascript. Wouldn't it be easier if I could just force the string to be UTF-8 and screw everything else? So I found toUTF8() PHP function. I've ported toUTF8() function (truly, the whole Encoding class) by Sebastián Grignoli to AutoIt. It offers useful functions to force a string to be in a specified charset in a really easy way. From the readme file: Usage $utf8_string = toUTF8($utf8_or_latin1_or_mixed_string) $latin1_string = toLatin1($utf8_or_latin1_or_mixed_string) Also: $utf8_string = fixUTF8($garbled_utf8_string) fixUTF8() converts the string to UTF-8 repeatedly until make sure it has only UTF-8 valid chars (it's really UTF-8). Example: #include 'forceutf8.au3' MsgBox(0, '', fixUTF8( 'ãé' ) ) Will output: ãé Note that it's just a port. If you look at both the source codes together (PHP and AutoIt), you'll see that they're exactly the same thing, but in different approaches (PHP arrays converted to Scripting.Dictionary objects, function renames, syntax porting, a few functions completely rewritten due to differences between PHP and AutoIt). Therefore, all credits goes to Sebastián Grignol. It seems that it works only with latin/roman alphabet (used by English). Downloads Download ZIP from Github Wanna help? Fork me on Github
Non-important short long story: I was facing several troubles when working with a webservice made in PHP and an AutoIt client. The AutoIt client had to send some data to the PHP webservice, then it would get back part of the data (with additional data) back to AutoIt, then send through Json to another webservice and end up in a TV system (huff). As I was using mostly Inet* functions, working with charsets became complicated, as it had to encode, decode, encode... and the mess is done. On the other end I was receiving a completely buggy string with several problems in accentuated characters (note that I live in Brazil, we speak portuguese that contains a lot of accented chars - Ááãç...). I tried and tried mixing utf_encodes and decodes everywhere, in PHP and Javascript. Wouldn't it be easier if I could just force the string to be UTF-8 and screw everything else? So I found toUTF8() PHP function. I've ported toUTF8() function (truly, the whole Encoding class) by Sebastián Grignoli to AutoIt. It offers useful functions to force a string to be in a specified charset in a really easy way. From the readme file: Usage $utf8_string = toUTF8($utf8_or_latin1_or_mixed_string) $latin1_string = toLatin1($utf8_or_latin1_or_mixed_string) Also: $utf8_string = fixUTF8($garbled_utf8_string) fixUTF8() converts the string to UTF-8 repeatedly until make sure it has only UTF-8 valid chars (it's really UTF-8). Example: #include 'forceutf8.au3' MsgBox(0, '', fixUTF8( 'ãé' ) ) Will output: ãé Note that it's just a port. If you look at both the source codes together (PHP and AutoIt), you'll see that they're exactly the same thing, but in different approaches (PHP arrays converted to Scripting.Dictionary objects, function renames, syntax porting, a few functions completely rewritten due to differences between PHP and AutoIt). Therefore, all credits goes to Sebastián Grignol. It seems that it works only with latin/roman alphabet (used by English). Downloads Download ZIP from Github Wanna help? Fork me on Github -
sqlite database written in ANSI code reading?The current version is based on UTF 8 encoding to read and write。 UNICODE or ANSI transfer method
-
I made a small program that should get the unicode code of an array, save it in a variable, and write it into an file. That should be done for every array of a string. For $i = 0 To $len Step 1 ; $len is the length of the text I enter previously $tmp0 = ChrW($text[$i]) ; $text is the text FileWrite($f, $tmp0 & @CRLF) ; $f is the file I write into $tmp0 = "" Next Building and compiling finish without raising warnings or errors, but the program fails when it's supposed to get the unicode code of that array... The error message says "Line 357 (File "D:\documents\coding\Crypt\Crypt.exe"): Error: Subscript used on non-accessible variable." My code ends at line 141, so it's not a problem with my code as such. I'd say that ChrW() isn't able to handle the variable I give it. I don't think it's a problem with the string, but I suspect that it's because I use a variable as an index ($text[$i]). If my clue was right, how do I fix it? If not, what could be the problem? Thanks for the help!
-
 Hello, can anybody tell me what is wrong with the uincode version of my C Run() function? Ansi Version works fine, but I have no clue why CreateProcess does not work in Unicode. #include <windows.h> int RunA(LPSTR szRun) { PROCESS_INFORMATION pi; STARTUPINFOA si; ZeroMemory(&si, sizeof(si)); si.cb = sizeof(si); ZeroMemory(&pi, sizeof(pi)); char szDir[1024]; GetCurrentDirectoryA(sizeof(szDir), szDir); if (!CreateProcessA(NULL, szRun, NULL, NULL, FALSE, 0, NULL, szDir, &si, &pi)) { return 1; } CloseHandle(pi.hThread); return 0; } int RunW(LPWSTR szRun) { PROCESS_INFORMATION pi; STARTUPINFOW si; ZeroMemory(&si, sizeof(si)); si.cb = sizeof(si); ZeroMemory(&pi, sizeof(pi)); wchar_t szDir[1024]; GetCurrentDirectoryW(sizeof(szDir), szDir); if (!CreateProcessW(NULL, szRun, NULL, NULL, FALSE, 0, NULL, szDir, &si, &pi)) { return 1; } CloseHandle(pi.hThread); return 0; } int WINAPI WinMain(HINSTANCE hInstance, HINSTANCE hPrevInstance, LPSTR lpCmdLine, int nCmdShow) { if (RunA("calc.exe")) { MessageBox(NULL, TEXT("Failure ANSI version"), TEXT("CreateProcess"), MB_ICONERROR); return 1; } /* // Why does the unicode function crash ?? if (RunW(L"notepad.exe")) { MessageBox(NULL, TEXT("Failure UNICODE version"), TEXT("CreateProcess"), MB_ICONERROR); return 1; } */ return 0; }
Hello, can anybody tell me what is wrong with the uincode version of my C Run() function? Ansi Version works fine, but I have no clue why CreateProcess does not work in Unicode. #include <windows.h> int RunA(LPSTR szRun) { PROCESS_INFORMATION pi; STARTUPINFOA si; ZeroMemory(&si, sizeof(si)); si.cb = sizeof(si); ZeroMemory(&pi, sizeof(pi)); char szDir[1024]; GetCurrentDirectoryA(sizeof(szDir), szDir); if (!CreateProcessA(NULL, szRun, NULL, NULL, FALSE, 0, NULL, szDir, &si, &pi)) { return 1; } CloseHandle(pi.hThread); return 0; } int RunW(LPWSTR szRun) { PROCESS_INFORMATION pi; STARTUPINFOW si; ZeroMemory(&si, sizeof(si)); si.cb = sizeof(si); ZeroMemory(&pi, sizeof(pi)); wchar_t szDir[1024]; GetCurrentDirectoryW(sizeof(szDir), szDir); if (!CreateProcessW(NULL, szRun, NULL, NULL, FALSE, 0, NULL, szDir, &si, &pi)) { return 1; } CloseHandle(pi.hThread); return 0; } int WINAPI WinMain(HINSTANCE hInstance, HINSTANCE hPrevInstance, LPSTR lpCmdLine, int nCmdShow) { if (RunA("calc.exe")) { MessageBox(NULL, TEXT("Failure ANSI version"), TEXT("CreateProcess"), MB_ICONERROR); return 1; } /* // Why does the unicode function crash ?? if (RunW(L"notepad.exe")) { MessageBox(NULL, TEXT("Failure UNICODE version"), TEXT("CreateProcess"), MB_ICONERROR); return 1; } */ return 0; } -
I do not like Charmap, it's too small and you can't test a character with another font, you only get all chars for each font so it's not very handy. SpecialCharactersViewer permit with the Segoe UI Symbol font to display a maximum ( not all! ) of Ascii and Unicode characters. Simple click on a char and the corresponding Chr or ChrW code is displayed. Free to you to choose another font for see if the selected character can be used with. Windows XP do not have Segoe UI Symbol font, so it's more for Win7/Win8 users... Previous downloads : 100 Source : SpecialCharactersViewer v1.0.1.0.au3 Executable : SpecialCharactersViewer.exe.html (Once this html file downloaded, double click on it for start the download) Will be added to the next version of SciTE Hopper. Hope it can help !
- 16 replies
-
- 4
-

-
- ascii
- Characters
- (and 3 more)
-
These functions handle ANSI and unicode inifiles similar to IniRead, IniWrite and IniDelete. _WinAPI_WritePrivateProfileStringW _WinAPI_GetPrivateProfileStringW So you can read from unicode inifiles created from other programs or perhaps read and write to your own inifiles. I was unable to figure out how the API function of WritePrivateProfileStringW can create a unicode file initially so I instead used FileOpen to create a unicode file and write the 1st entry to achieve this. Further use uses WritePrivateProfileStringW is ok to handle the unicode entries. ANSI file creation is done by WritePrivateProfileStringW by default. Deletion of keys and sections may need use of Null which is in AutoIt 3.3.9.0 and later. I put comments with the code so hopefully understandable to you. The functions use a similar parameter syntax to IniRead and IniWrite. _WinAPI_WritePrivateProfileStringW has an additional parameter to handle the flag passed to FileOpen for the initial creation of the inifile. _WinAPI_GetPrivateProfileStringW has an additional parameter in case you want the buffer that holds the return value within the UDF to be larger. The example has some russian text in it so you need to save it in a unicode script for correct testing. Example ; show message if script is not unicode. Unicode text in this script requires it to be UTF encoded. ; if needed in Scite, use menu bar, File -> Encoding -> UTF (any UTF type that suits you) and save the script. If Not FileGetEncoding(@ScriptFullPath) Then MsgBox(0, @ScriptName, 'Script is not unicode') ; write to ini file $return = _WinAPI_WritePrivateProfileStringW("test.ini", 'russian', 'Open', 'Открыть', 0x21) _Notify('Write', $return) ; read from ini file $return = _WinAPI_GetPrivateProfileStringW("test.ini", 'russian', 'Open', 'Default') _Notify('Read', $return) #cs AutoIt 3.3.9.0 or later using Null keyword ; setting $sValue parameter with Null keyword will delete a key using AutoIt 3.3.9.x or later. $return = _WinAPI_WritePrivateProfileStringW("test.ini", 'russian', 'Open', Null) ; setting $sKey parameter with Null keyword will delete a section using AutoIt 3.3.9.x or later. $return = _WinAPI_WritePrivateProfileStringW("test.ini", 'russian', Null, Null) ; setting $sSection parameter with Null keyword will flush using AutoIt 3.3.9.x or later. $return = _WinAPI_WritePrivateProfileStringW("test.ini", Null, Null, Null) #ce ; More info of an API that mimics these functions and explains use of Null at http://code.google.com/p/privateprofilestring/ Func _Notify($title, $return = 0, $error = @error, $extended = @extended) ; notify results from other function calls MsgBox(StringRegExpReplace($error, '-{0,1}([1-9])[0-9]*', '0x30'), $title, _ '@error = ' & $error & @CRLF & _ '@extended = ' & $extended & @CRLF & _ '$return = ' & $return _ ) EndFunc User defined functions ; #FUNCTION# ==================================================================================================================== ; Name...........: _WinAPI_WritePrivateProfileStringW ; Description ...: Write to ANSI and unicode encoded ini files ; Syntax.........: _WinAPI_WritePrivateProfileStringW($sFileName, $sSection, $sKey, $sValue[, $iMode = 1]) ; Parameters ....: $sFileName - The filename of the .ini file ; $sSection - The section name in the .ini file ; $sKey - The key name in the in the .ini file ; $sValue - The value to write/change ; $iMode - Refer to FileOpen mode parameter ; Return values .: Success - Not 0 ; Failure - 0 ; @error 1 to 5 - Refer to DllCall ; @error 6 - FileOpen failed to open a handle to create the file ; Author ........: MHz ; Modified.......: ; Remarks .......: Similar to IniWrite but uses unicode API calls. If $sValue is Null then $sKey is deleted. If $sKey is Null, ; then $sSection is deleted. If $sSection, $sKey and $sValue are all Null, then $sFileName is ; flushed. *** Null is a keyword that only exists in AutoIt3 versions 3.3.9.x and later *** ; Related .......: DllCall, FileOpen, IniWrite ; Link ..........: http://msdn.microsoft.com/en-us/library/windows/desktop/ms725501%28v=vs.85%29.aspx ; http://msdn.microsoft.com/en-us/library/windows/desktop/bb773660%28v=vs.85%29.aspx ; Example .......: Yes ; =============================================================================================================================== Func _WinAPI_WritePrivateProfileStringW($sFileName, $sSection, $sKey, $sValue, $iMode = 1) Local $handle_write, $ret ; check if path is relative and make it absolute if it is relative $ret = DllCall('Shlwapi.dll', 'bool', 'PathIsRelativeW', 'wstr', $sFileName); lpszPath If Not @error And $ret[0] Then $sFileName = @WorkingDir & '\' & $sFileName ; create a unicode encoded file if needed and write the entry If Not FileExists($sFileName) And $iMode > 0x20 Then $handle_write = FileOpen($sFileName, $iMode) If $handle_write = -1 Then Return SetError(6, 0, 0) FileWrite($handle_write, '[' & $sSection & ']' & @CRLF & $sKey & '=' & $sValue & @CRLF) FileClose($handle_write) Return 1 EndIf ; write to the ini file. $ret[0] will contain nonzero if successful $ret = DllCall('Kernel32.dll', 'bool', 'WritePrivateProfileStringW', _ 'wstr', $sSection, _ 'wstr', $sKey, _ 'wstr', $sValue, _ 'wstr', $sFileName _ ); lpAppName, lpKeyName, lpString, lpFileName If @error Then Return SetError(@error, @extended, 0) Return SetExtended(0, $ret[0]) EndFunc ; #FUNCTION# ==================================================================================================================== ; Name...........: _WinAPI_GetPrivateProfileStringW ; Description ...: Read from ANSI and unicode encoded ini files ; Syntax.........: _WinAPI_GetPrivateProfileStringW($sFileName, $sSection, $sKey[, $sDefault = ''[, $iBufferSize = 65536]]) ; Parameters ....: $sFileName - The filename of the .ini file ; $sSection - The section name in the .ini file ; $sKey - The key name in the in the .ini file ; $sDefault - The default value to return if the requested key is not found ; $iBufferSize - Adjustable buffer size which contains the chars from the API call ; Return values .: Success - Returns the requested key value ; Failure - Returns the default string if requested key not found ; @error 1 to 5 - Refer to DllCall ; Author ........: MHz ; Modified.......: ; Remarks .......: Similar to IniRead but uses unicode API calls ; Related .......: IniRead ; Link ..........: http://msdn.microsoft.com/en-us/library/windows/desktop/ms724353%28v=vs.85%29.aspx ; http://msdn.microsoft.com/en-us/library/windows/desktop/bb773660%28v=vs.85%29.aspx ; Example .......: Yes ; =============================================================================================================================== Func _WinAPI_GetPrivateProfileStringW($sFileName, $sSection, $sKey, $sDefault = '', $iBufferSize = 65536) Local $buffer, $ret ; check if path is relative and make it absolute if it is relative $ret = DllCall('Shlwapi.dll', 'bool', 'PathIsRelativeW', 'wstr', $sFileName); lpszPath If Not @error And $ret[0] Then $sFileName = @WorkingDir & '\' & $sFileName ; create a buffer to hold the returned string $buffer = DllStructCreate('wchar[' & $iBufferSize & ']') ; read from the ini file. $ret[0] will contain number of chars returned $ret = DllCall('Kernel32.dll', 'dword', 'GetPrivateProfileStringW', _ 'wstr', $sSection, _ 'wstr', $sKey, _ 'wstr', $sDefault, _ 'ptr', DllStructGetPtr($buffer), _ 'dword', DllStructGetSize($buffer), _ 'wstr', $sFileName _ ); lpAppName, lpKeyName, lpDefault, lpReturnedString, nSize, lpFileName If @error Then SetError(@error, @extended, $sDefault) Return SetExtended($ret[0], DllStructGetData($buffer, 1)) EndFunc Thanks to AZJIO for some russian text for use in the example. Edit: Updated with summary correction by guiness in post #2
-
Not sure if this topic belongs here , but perhaps someone has helpful input since this could be a common situation. I have tried to use labels with Hindi fonts in Koda, but regardless of correct font selection (hindi font OR Arial Unicode) any string is converted into ????. Is KODA in general a unicode application or not ? Nothing is specified on their website that I can see. I know that compiled scripts work with unicode, no problem.
-
I have seen this question asked (and ) before, but my needs are a little different so I am only 90% of the way. Hope someone can give the final puzzle piece. Here is what I need: * from a text file which is Unicode UTF8 (BOM), read strings one by one * create a BMP file of 300 px high and place textline on it - BMP must be 2 bit (b/w only) * save BMP * read next line In the end there is as many different BMPs as there are lines in text file. I know how to operate _GDI_GraphicsDrawstring, that part is simple. But what I can't find the answer to is 1) how to calculate the space needed horizontally by a given string in 300 px height 2) how to create a white-background BMP in memory, so it can be populated and written to disc. Point 2) is the most important, the auto-font-size-calculation can come later. For now it's trial and error. Referring to ImageMagick, this would be $image->ReadImage('canvas:white'); The purpose is to use images in an industrial microcontroller. Therefore the need for 2bit BMP and 300px exact in height. Thanks for any help